Table of Content
- What is Apache Airflow?
- Benefits of Using Apache Airflow Technology
- Airflow Configuration and Installation
- Krasamo’s Airflow Consulting Services
- Apache Airflow ETL Pipelines andMachine Learning Concepts
- Tasks and Dependencies
- Airflow Operators and SensorsAirflow Hooks
- Branching and Trigger Rules
- Triggering Tasks
- Training ML Models
- Templating in Airflow
- Cloud Services—Airflow as a Service
- Airflow Docker
- Apache Airflow Executors
- Airflow Kubernetes
Build and run ETL pipelines as code with the Apache Airflow orchestrator. Integrate data from internal and external sources connecting to third-party APIs and data stores in a modular architecture.
What is Apache Airflow?
Apache Airflow is an open-source data pipeline orchestration platform (workflow scheduler).
Apache Airflow orchestrates components for processing data in data pipelines across distributed systems. Data pipelines involve the process of executing tasks in a specific order.
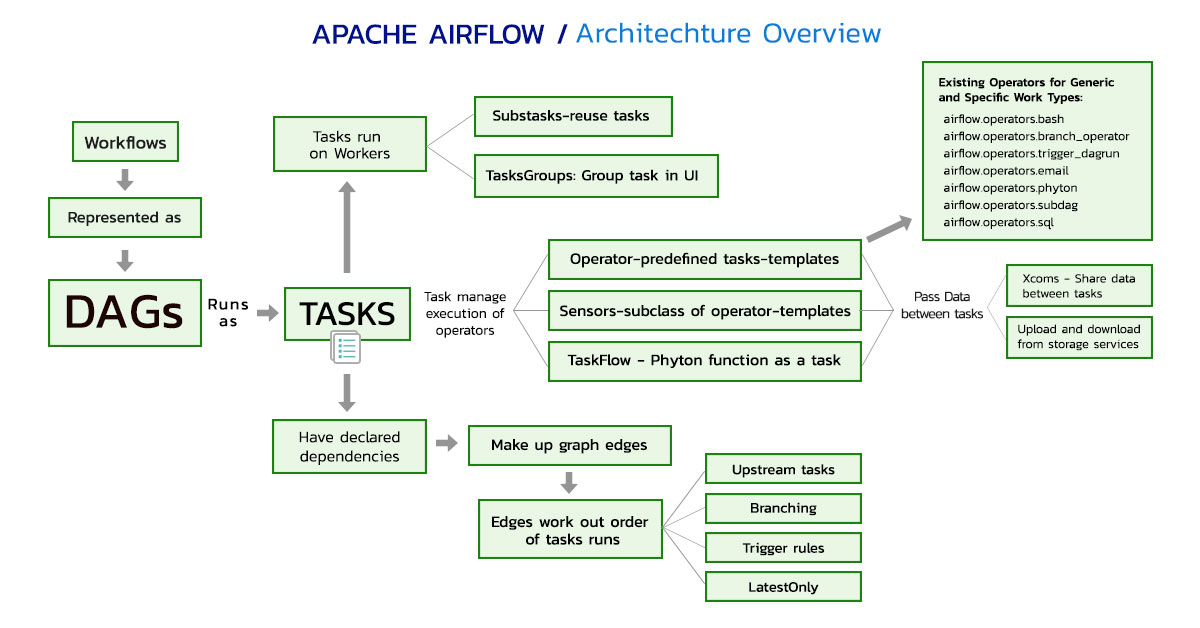
Apache Airflow is designed to express ETL pipelines as code and represent tasks as graphs that run with defined relationships and dependencies. A Directed Acrylic Graph (DAG) is a graph coded in Python that represent the overall pipeline with a clear execution path—and without loops or circular dependencies.
The DAG defines the tasks and executions, running order, and frequency. Tasks are represented as nodes and have upstream and downstream dependencies that are declared to create the DAG structure. The DAG is the center that connects all the Airflow operators and lets you express dependencies between different stages in the pipeline. Each task is scheduled or triggered after an upstream task is completed and implemented as a Python script—defined in DAG files that contain metadata about its execution.
Airflow solutions allow users the ability to run thousands of tasks and have many plugins and built-in operators available that integrate jobs in external systems or are customized for specific use cases.
Apache Airflow solutions are used for batch data pipelines. They can create instances in Airflow environments to connect quickly with APIs and databases using hooks (interfaces), without writing low-level code. Hooks integrate with connections with encrypted credentials and API tokens stored as metadata.
The Airflow UI provides features and visualizations (workflow status) that give insights for understanding the pipeline and the DAG runs. The dashboard provides several ways to visualize and manage the DAG runs and tasks instance actions, dependencies, schedule runs, states, code viewing, etc.
Benefits of Using Apache Airflow Technology
- Creates complex and efficient pipelines
- Open source and flexibility
- Integrates with cloud services and databases
- Allows incremental processing and easy re-computation
- Allows monitoring and visualizing of pipeline runs
- Ideal for batch-oriented pipelines
- Easy to combine with tools for expanded capabilities
- Allows backfilling—can perform historical runs or reprocess data
Write, schedule, iterate, and monitor data pipelines (workflows) and tasks with Krasamo’s Apache Airflow Consulting Services.
Airflow Configuration and Installation
- Define Pipeline Structure—Define DAG of tasks and dependencies coded in Python in a DAG file, creating workflows and DAG structure that allows executing operations.
- Airflow Scheduler—The scheduler checks and extracts (parses) tasks and dependencies from the files and determines task instances and set of conditions. The scheduler is set to run at specific times or discrete intervals and submits tasks to the executors.
- Airflow Executor—The task executor handles running tasks inside the scheduler as a default option or pushes task execution to Airflow workers. The executor registers the task state changes and handles task execution.
- Schedule DAG Intervals—Schedule intervals and parameters (param) to determine when the pipeline is run (triggered) for each DAG’s execution. Checks if dependencies are completed and adds tasks to the execution queue.
- Airflow Workers—Airflow workers pick up tasks from the queue and execute them, checking/retrieving results and passing them to Airflow’s metastore.
- Airflow Webserver—Airflow Webserver (HTTP Server) is a web interface used to visualize and monitor DAG task runs and results and to debug their behavior.
- Airflow Database/Metastore–Metadata—Database stores components, states, and provides the status of DAGs and tasks, connections, and variables (store credentials). MySQL or Postgres databases are preconfigured to access resources and store encrypted credentials.
- DAG File Folder—The DAG file folder contains DAG definitions of custom components (operators, hooks, and sensors) and metadata about its execution. It is accessible to the Scheduler, Webserver, and executor processes.
- Airflow Failures—Failed tasks can happen, and Airflow can wait and retry or rerun tasks after failures and notify while successive dependent tasks stop running. Failed tasks are displayed in red on the graph and tree view of the Airflow UI, and the workflow restarts from the failure point.
Krasamo’s Airflow Consulting Services
- Airflow Configuration. Manage configuration, which is time-consuming and can be set in various ways. Configuring your pipelines requires defining DAGs and task dependencies, triggering rules, installing task executors and generic operators, and setting up or creating custom operators and hooks for interacting with external systems.
- Infrastructure Management. Design and maintain a modular architecture, as well as provide infrastructure management and provisioning.
- Operations. Assist with workflow implementation and execution, including installation of components and dependencies on the Airflow cluster.
- Phyton Development. Python developers create algorithms and custom code for building components (operators, hooks, and sensors), provide Python package development, set up CI/CD pipeline and Airflow tests, and manage Python environments.
Apache Airflow ETL Pipelines and
Machine Learning Concepts
Apache Airflow is a workflow automation tool with built-in frameworks that simplify setting up ETL jobs. Apache Airflow is a key component for building Machine Learning Models. You can create a ML model that correlates data from different data sets as input to feed a predictive model and reach a goal.
Airflow DAGs extract, transform, and load (ETL) datasets. Airflow allows users to run data sets independently as coded graphs (DAG) and execute them in parallel as branches. Furthermore, Airflow runs tasks incrementally, which is very efficient as failing tasks and downstream dependencies are only run when failures occur.
Tasks and Dependencies
In practice, many problems require creating pipelines with many tasks and dependencies that require greater flexibility that can be approached by defining workflows as code. Apache Airflow is a workflow management solution with key features especially suited for Machine Learning use cases.
Machine learning models require training data from combined data sets. Data may also come from different systems and require separate code paths to be ingested from branches within tasks or different chains of tasks. Also, developing two sets of tasks within the DAG structure might prove to be more flexible for specific scenarios.
Airflow Operators and Sensors
Airflow operators represent tasks or predefined task templates (premade or reusable) used to build DAGs. Many operators are available, built-in, or may come installed in the provider packages.
Operators perform actions, move data, or specify a condition. Airflow sensors are operators that run until a condition is met. Airflow allows users to create their own Airflow operator (custom operators) and sensors that can be shared with the community.
Airflow Hooks
Airflow Hooks are interfaces to external systems and a component of operators. They can encompass complex code and be reused. Creating a custom hook requires defining parameters, arguments, connections, building methods, and configuration details.
Branching and Trigger Rules
Data engineers carefully design branching tasks with the appropriate Airflow operators and consider upstream and downstream task relationships, execution orders, and connections with the DAGs. Also, operators create trigger rules and conditions used to define tasks behaviors and relationships that determine when tasks are executed. Krasamo engineers ensure the correct deployment logic and conditions when building data pipelines.
Triggering Tasks
Developing logic for creating workflows and triggering DAGs based on actions or time intervals is fundamental. A timeline is created to define the starting times for the workflow of data that comes from different locations and arrives at different times. The DAG may require using Airflow sensors (a subclass of Airflow operators) to check that conditions are met and data is available to start. DAGs can also be triggered from REST APIs and the command line interface (CLI). The triggering approach will depend on possible scenarios and the complexity of the workflow.
Training ML Models
Once the data is correctly loaded and transformed to a suitable format, users can train the models. Airflow pipelines allow to continuously feed new data to retrain models and automate their redeployment. In addition, users can do templating to capture configuration arguments to ensure an effective model retraining process and idempotent tasks.
Templating in Airflow
Templating in Airflow allows making computations incrementally by processing smaller sets of data and setting dynamic variables.
Airflow has a template functionality with built-in parameters and macros that help users insert a value to a variable in an operator during task runtime to execute all components. Variables or expressions are replaced at runtime by a template string argument.
Jinga is a powerful templating tool that works with Airflow. It is not in the scope of this paper to discuss the technical details. Readers may learn more about templates by visiting these pages in the Airflow documentation: Templates reference and Jinja Templating.
Cloud Services—Airflow as a Service
Krasamo can design architectures and set up deployments in cloud platforms, using built-in operators (interfaces) to integrate and implement as an Airflow partner. Also, our teams can leverage specific cloud components and app development for data-intensive applications.
The cloud platform provides a Software Development Kit (SDK) package with the components (command-line tools, Phyton libraries, etc.) that provide the functionality to connect the pipeline. The pipeline connects through an application programming interface (API, specifically Airflow API) or Airflow operator to send requests to the cloud service.
Installing provider packages extends the capabilities of Apache Airflow to communicate and integrate with cloud services or external systems. Providers contain Airflow operators, sensors, hooks, and transfer operators, and serve to extend capabilities and functionality available as Core Extensions.
Using cloud services eases the development and deployment of ML models as Airflow supports most cloud services.
- Cloud Composer. Google Cloud Platform (GCP) offers an orchestration service (Airflow solutions) to manage workflows on Apache Airflow. Users can access the Airflow API to perform tasks and trigger cloud functions when specific events occur. Users can also create an Apache Airflow environment using Cloud Composer and deploy it into a Google Kubernetes Engine cluster (Airflow Kubernetes).
- Amazon Managed Workflows for Apache Airflow (MWAA). MWAA Airflow, also known as AWS Airflow, is a commercial managed orchestration service for Apache Airflow that sets up and operates end-to-end data pipelines at scale in the cloud.
Integration of data pipelines with cloud services components can be quite challenging. At Krasamo, our job is to use our experience and expertise to create the pipelines and then provide our clients with the added benefits of a turnkey processing solution (completed, installed, and ready to use).
Airflow Docker
Running tasks in containers using Docker helps simplify the development and maintenance of running multiple DAGs with many operators. However, using different operators can become complex due to many implementations and dependencies. DAGs may be implemented using Airflow Docker—a single operator with one set of dependencies to manage tasks and help reduce complexities.
Airflow Docker containerizes tasks and dependencies that function independently (isolated) from the host operating system and manage interactions with a container engine (Docker). The environment can be accessed by running the command line interface (CLI), web interface, or Airflow API.
Airflow Docker has the advantage of defining several tasks by building images (Docker Images) for each task with specific arguments and executing them in containers with dependencies using one operator (DockerOperator). Installing dependencies only in Docker avoids conflicts between tasks. In addition, container images make it easier to develop and test functions (debug) against one operator independently from the orchestration layer.
Apache Airflow has Docker images released by the community as reference images for supported Python versions. Visit the Docker Hub Apache Airflow documentation for more information. To get started with Docker, prepare the environment on the operating system, install a Docker engine, create Dockerfiles and directories, and initialize the database. Next, fetch a docker-compose.yaml file with service definitions and Airflow configuration. Finally, build Airflow DAGs from containerized tasks and run containers on Airflow.
Users can also get Airflow up and running by setting up a Python package in a Docker Container. The use of Docker can be started with CeleryExecutor or Docker Compose to deploy in Airflow.
Apache Airflow Executors
An Airflow executor is a task execution process that utilizes resources to place task instances on a queue to complete or execute.
Configure the execution mode process for tasks to run:
- Celery Executor (CeleryExecutor, a queue mechanism):
CeleryExecutor is a remote executor that defines multiple task queues to run and scales workers faster running workflows over multiple machines. The Celery executor has two components that communicate: Broker (a queueing mechanism) and result backend. - Local Executor (LocalExecutor):
Local Executor can run tasks in parallel in a single machine. It sends tasks to a queue for processing by a single local worker. Local Executor is ideal for testing. - Kubernetes Executor (KubernetesExecutor):
The Kubernetes Executor is a remote executor that allows distributing Airflow workflows in multiple machines and running on a Kubernetes cluster. DAGs run tasks in Kubernetes Pods. This is the most current type of Airflow configuration. - Sequential Executor (SequentialExecutor):
The Sequential Executor is configured as a default; it executes tasks locally (local executor) on a single machine and runs tasks in a sequential order one by one. It is mainly used for testing purposes (debugging).
Airflow Kubernetes
Infrastructure running on Kubernetes is advantageous for scaling by running Airflow from Kubernetes clusters. However, Airflow workflow deployments for various use cases may have to use different libraries and can create issues in managing dependencies. By working with the Airflow Kubernetes operator, clients may launch Kubernetes Pods (container applications) and configurations that provide better control of their environment and resources to orchestrate ETL jobs. Tasks are run as containers inside Pods (using AirflowPodOperator).
There are many benefits of using Airflow Kubernetes operators. By running tasks on Docker containers, users can add new functionality using the same operator (Airflow Kubernetes operator or AirflowPodOperator ) and thereby avoid coding new plugins. Kubernetes Pods are configured with specific configuration options to secure sensitive data (secrets) and environment variables. Setting up Airflow to run on Kubernetes operators requires containerizing ETL code, which allows adding nodes and running more ETL jobs with different environment requirements as well as improving scalability and resource utilization.